Introducing the Intel Gaudi 3 AI accelerator. With performance, scalability and efficiency that gives more choice to more customers, Intel Gaudi 3 accelerators help Enterprises unlock insights, innovations and income.
With the growing demand for generative AI compute, has come increasing demand for solution alternatives that give customers choice. The Intel Gaudi 3 AI accelerator is designed to deliver choice with:
Price-Performance Efficiency
Great price-performance so enterprise AI teams can train more, deploy more and spend less.
Massive Scalability
With 24 x 200 GbE ports of industry-standard Ethernet built into every Gaudi 3 accelerator, customers can flexibly scale clusters to fit any AI workloads—from a single rack to multi-thousand-node clusters.
Easy-to-use Development Platform
Gaudi software is designed to enable developers to deploy today’s popular models with open software that integrates the PyTorch framework and supports thousands of Hugging Face transformer and diffusion models.
Support by Intel AI Cloud
Developers can play on the Intel Gaudi AI cloud to learn how easy it is to develop and deploy generative AI models on the Gaudi platform.
Gen over Gen advancements
2x AI compute(FP8)
4x AI compute(BF16)
2x Network Bandwidth
1.5x Memory Bandwidth
*Specification advances of Intel Gaudi 3 accelerator vs. Intel Gaudi 2 accelerator
Intel Gaudi 3 accelerator performance vs. Nvidia GPUs
1.5x faster time-to-train than NV H100 on average1
1.3x faster inference than NV H200 on average2
1.5x faster inference than NV H100 on average3
1.4x higher inference power efficiency than NV H100 on average4
Efficiency, performance and scale for data center AI workloads
Intel Gaudi 3 AI accelerators support state-of-the-art generative AI and LLMs for the datacenter and pair with Xeon Scalable Processors, the host CPU of choice for leading AI systems, to deliver enterprise performance and reliability.
3D Generation
Summarization
Video Generation
Q&A
Image Generation
Classification
Text Generation
Translation
Sentiment
Architected at Inception for Gen AI Training and Inference
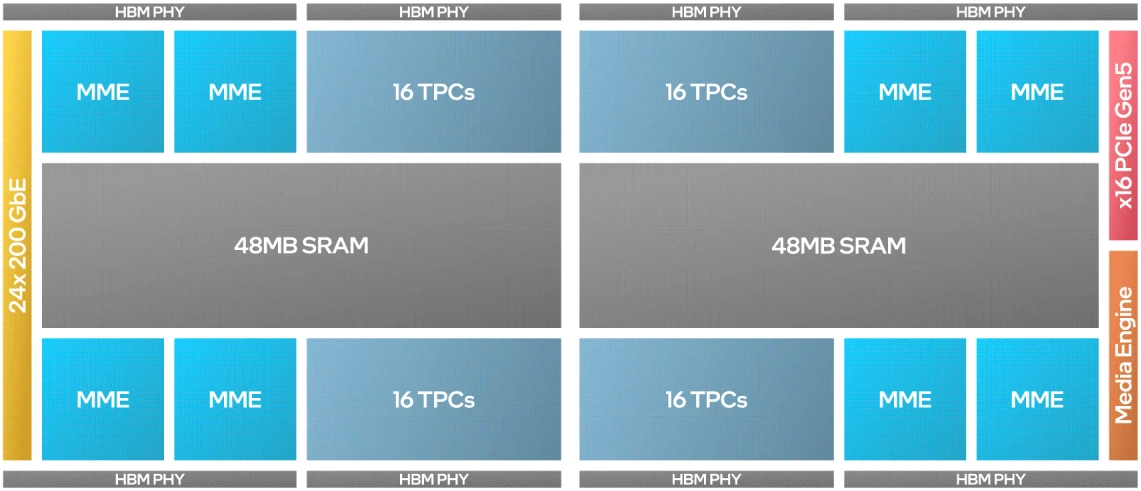
Intel Gaudi 3 accelerator with L2 cache for every 2 MME and 16 TPC unit
The Intel Gaudi 3 accelerator challenges the industry’s legacy performance leader with speed and efficiency born from its AI compute design.
The Intel Gaudi 3 accelerator architecture features heterogenous compute engines—eight matrix multiplication engines (MME), 64 fully programmable Tensor Processor Cores (TPCs) and supports popular data types required for deep learning: FP32, TF32, BF16, FP16 & FP8. For details on how the Intel Gaudi 3 accelerator architecture delivers AI compute performance more efficiently.
Putting performance into practice has never been this easy.
Intel Gaudi software eases development with integration of the PyTorch framework, the foundation of the majority of Gen AI and LLM development. Code migration on PyTorch from Nvidia GPUs to Intel Gaudi accelerators requires only 3 to 5 lines of code. Intel Gaudi software on the Optimum Habana Library also gives developers easy access to thousands of popular gen transformer and diffusion models on the Hugging Face hub. For more information developing on Intel Gaudi software.
An introduction to game-changing Intel Gaudi 3 AI accelerators:
You’ve got choice with Intel Gaudi 3 accelerators
Every enterprise has different AI compute requirements with many considerations—desired system performance, scale, power, footprint and more.
To address your enterprise’s specific needs, Intel Gaudi 3 accelerator provides these hardware options:
Intel Gaudi 3 AI Accelerator HL-325L OAM Mezzanine Card
The Intel Gaudi 3 Al accelerator mezzanine card (HL-325L) is designed for massive scale out in data centers. The training and inference accelerator is built on the Intel Gaudi 5th generation high-efficiency heterogeneous architecture, now in 5nm process technology with state-of-the-art performance, scalability and power efficiency. The HL-325L complies with the OCP OAM v2.O (Open Compute Platform-Open Accelerator Module) specifications, giving customers system design flexibility with choice among products conforming to the spec. The Intel® Gaudi® 3 processor features 8 MME engines and 64 fully programmable Tensor Processor Cores (TPCs) natively designed to accelerate a wide array of deep learning workloads while also providing the flexibility to optimize and innovate. The accelerator card is equipped with 128 GB of HBM2E memory and 96 MB of SRAM and supports card level TDP of up to 900 watts.
The Intel Gaudi 3 AI accelerator offers unmatched scalability of 9.6 Terabits per second bi-directional networking capacity with native integration of 24x200 GbE RoCE v2 RDMA ports, enabling all-to-all communication via direct routing or via standard Ethernet switching. This on-chip networking integration gives customers capacity and flexibility to build systems of any scale. The Intel Gaudi 3 accelerator integrates dedicated media processor for image and video decoding and pre-processing.
Intel Gaudi 3 AI Accelerator HL-325L Mezzanine Card
Host Interface
Memory
TDP
Scale-Out Interconnect
Form Factor
PCIe Gen 5.0 x 16
128GB HBM2E
900W
RDMA (RoCE v2) 24x200 Gbps
OCP Accelerator Module V2.0 Compliant
Technology Innovation
The Intel Gaudi 3 AI accelerator features a unique combination of technology innovations. As a high-performance and fully programmable Al processor, the accelerator is equipped with high memory bandwidth and capacity and designed for efficient scale-out based on standard Ethernet technology. With its wide array of connectivity options, the Intel Gaudi 3 accelerator enables system integrators to build training systems of any scale, from a single server to complete racks using a variety of Ethernet switches and scale-out topologies, all while using the same standards-based, scaleout technology.
Compute Technology
Based on the proven architecture of first-gen Intel Gaudi and Intel Gaudi 2, Intel Gaudi 3 accelerators leverage Intel’s fully programmable TPC and GEMM Engine, supporting the most advanced data types for Al, including FP8, BF16, FP16, TF32 and FP32. The TPC core was designed to support Deep Learning training and inference workloads. It is a VLIW SIMD vector processor with an instruction set and hardware that were tailored to serve these workloads efficiently.
Memory
Memory bandwidth and capacity are as important as compute capability. The Intel Gaudi 3 accelerator incorporates the most advanced HBM memory technology, supporting extremely high memory capacity of 128GB and total throughput of 3.7 TB/s. The cutting-edge HBM controller is optimized for both random access and linear access, providing record-breaking throughput in all access patterns.
Scale Out with Integrated RDMA
The Intel Gaudi 3 accelerator is “the only Al deep learning processor to integrate on-chip RDMA over converged Ethernet (RoCEv2) to interface with industry standard Ethernet networking. The Intel Gaudi 3 Al accelerator chip interconnect technology is based on 48 pairs of 112Gbps Tx/Rx PAM4 SerDes configured as 24 ports of 200 Gb Ethernet.
Intel Gaudi 3 AI Accelerator HL-338 PCIe Add-In Card
The Intel Gaudi 3 Al accelerator PCIe card (HL-338) is designed to deliver performance and efficiency in a standard PCIe card form factor. The training and inference accelerator is built on the Intel® Gaudi® 5th generation high-efficiency heterogeneous architecture, now in 5nm process technology with state-of-the-art performance, scalability and power efficiency. The HL-338 is a full-height, dual-slot PCIe card with a length of 10.5” and a card level TDP of up to 600 watts, providing customers with the flexibility to integrate into new or existing AI server designs. The Intel® Gaudi® 3 Al processor features 8 MME engines and 64 fully programmable Tensor Processor Cores (TPCs). The TPCs are natively designed to accelerate a wide array of deep learning workloads while also providing the flexibility to optimize and innovate. The accelerator card is equipped with 128 GB of HBM2E memory and 96 MB of on-die SRAM.
The Intel Gaudi 3 AI accelerator offers unmatched scalability with 9.6 Terabits per second bi-directional networking capacity with native integration of 24x200 GbE RoCE v2 RDMA ports, enabling all-to-all communication via direct routing or via standard Ethernet switching. This on-chip networking integration gives customers capacity and flexibility to build systems of any scale. The Intel Gaudi 3 accelerator integrates a dedicated media processor for image and video decoding and pre-processing. The RoCE v2 RDMA ports on the HL-338 are exposed through a gold-finger connector, which can utilize the HLTB-304 to connect 4 HL-338 cards, as well as 2 QSFP-112 connectors placed directly on the card.
Intel Gaudi 3 AI Accelerator HL-338 PCIe Card
Host Interface
Memory
TDP
Scale-Out Interconnect
Form Factor
PCIe Gen 5.0 x 16
128GB HBM2E
600W
RDMA (RoCE v2) 24x200 Gbps
Full-height, Double-wide, 10.5” length PCIe Card
Technology Innovation
The Intel Gaudi 3 AI accelerator features a unique combination of technology innovations. As a high-performance and fully programmable Al processor, the accelerator is equipped with high memory bandwidth and capacity designed for efficient scale-out based on standard Ethernet technology. With its wide array of connectivity options, the Intel® Gaudi® 3 accelerator enables system integrators to build training systems of any scale, from a single server to complete racks using a variety of Ethernet switches and scale-out topologies, all while using the same standards-based, scale-out technology.
Compute Technology
Based on the proven architecture of first-gen Intel Gaudi and Intel Gaudi 2, Intel Gaudi 3 accelerators leverage Intel’s fully programmable TPC and GEMM Engine, supporting the most advanced data types for Al, including FP8, BF16, FP16, TF32 and FP32. The TPC core was designed to support Deep Learning training and inference workloads. It is a VLIW SIMD vector processor with an instruction set and hardware that were tailored to serve these workloads efficiently.
Memory
Memory bandwidth and capacity are as important as compute capability. The Intel® Gaudi® 3 accelerator incorporates the most advanced HBM memory technology, supporting extremely high memory capacity of 128GB and total throughput of 3.7 TB/s. The cutting-edge HBM controller is optimized for both random access and linear access, providing record-breaking throughput in all access patterns.
Scale Out with Integrated RDMA
The Intel Gaudi 3 accelerator is the only Al deep learning processor to integrate on-chip RDMA over converged Ethernet (RoCE v2) to interface with industry standard Ethernet networking. The Intel® Gaudi® 3 Al accelerator chip interconnect technology is based on 48 pairs of 112Gbps Tx/Rx PAM4 SerDes configured as 24 ports of 200 Gb Ethernet.
Intel Gaudi 3 AI Accelerator HLB-325 Baseboard
The Intel Gaudi 3 baseboard (HLB-325) accommodates 8 Intel Gaudi 3 AI accelerator OAM mezzanine cards and provides customers a module subsystem that is easy to migrate into their AI server designs. The HLB-325 provides direct all-to-all connectivity with 4.2 Tera-Bytes (TB) per second of bi-directional bandwidth between the 8 Intel® Gaudi® 3 accelerators, without requiring a separate switching IC. In addition, the HLB325 provides an additional 1.2TB per second of bi-directional scale-out bandwidth through 6 OSFP connectors, enabling massive scale-out in data centers using Ethernet switches.
Designed to enable efficient and simple integration into AI servers, the HLB-325 derives the majority of its power from 54V power input, only requiring a separate 12V input for standby. On-board PCIe retimers and scale-out retimers provide robust signal integrity of the highspeed signals coming to and from the baseboard. The 417mm width and 585mm length of the HLB-325 allow it to be incorporated into a variety of new and existing 19” AI accelerator server designs to provide state-of-the-art performance, scalability and power efficiency.
HLFB-325L Integrated Subsystem
The Intel Gaudi 3 baseboard and 8 Intel Gaudi 3 AI accelerator mezzanine cards are offered as an integrated subsystem to simplify customers’ server manufacturing operations. The HLFB-325L is the combination of one HLB-325 baseboard and 8 HL-325L Intel Gaudi 3 AI accelerator mezzanine cards, tested together to enhance quality and shipped as a whole subsystem to ease high-volume server assembly and manufacturing
Intel Gaudi 3 AI Accelerator HL-325L Mezzanine Card